
Mathematical Modeling Of Information Security Risks Inherent In Using Blockchain Technology

Abstract
A primary technology underpinning the creation and operation of the digital economy is blockchain or, more precisely, distributed ledger technology (DLT). The main reason for implementing blockchain in businesses is streamlining business processes by restructuring them to enhance their efficiency. Today the leaders in implementing DLT are the finance, energy, retail, and public sectors. These sectors all face the important problem of making the interaction between business processes transparent. Although it is being actively implemented and used in various industries, the technology has its shortcomings – information security risks involved in its use: the low performance of block network nodes; complicated network scalability; lack of legal regulation creates a threat to the blockchain environment; large amount of data stored on the network and problems relating to block network manageability and data confidentiality. The main cause of these shortcomings is that blockchain is decentralized. Thus, the main advantage of the technology also gives rise to a whole array of information security risks that need to be addressed. To form theoretical foundations for identifying information security risks, it is necessary to formulate basic approaches to creating fuzzy measuring scales and determine fuzzy operations on object sets, a list of membership functions, operations on linguistic values, and fuzzification and defuzzification functions.
Keywords: Digital economyblockchaininformation risksfuzzy measuring scalesmembership functions
Introduction
When identifying information security risks, one should use the fuzzy-inference mechanism. This mechanism combines the basic concepts of fuzzy-set theory: membership functions, fuzzy operations, fuzzy implication and composition, and linguistic variables. Thus, the use of this mechanism is a comprehensive approach to identifying information security risks, since it allows one to factor in the degree of the quality of assessing how effective the security of information resources is (using the associated fuzzy scale); the required level of protection; and the logical-inference rules that determine the level of information security risk.
Problem Statement
First of all, forming the model requires determining a fuzzy set of objects and assigning associated membership functions for each variable
Constructing the membership function involves using restrictions based on information about the functioning of the model. Most practical tasks are characterized by many criteria that can impose restrictions on the membership function, and this dictates the use of generalized indicators ( Korablev, 2016). We will form a set of eight fuzzy measuring scales to assess the components of the model: confidentiality, integrity, availability, value, impact, vulnerability of external borders, risk, and loss. For each scale, we need to provide a specific description and calculate the membership functions for fuzzy values.
When constructing the membership functions, we used carriers consistent with Harrington’s desirability function. The intersection of the carriers is determined by a value of 0.08 or ± 0.04 from the center of the common part. We limit the measuring scales to the segment [0,1], where 0 is the minimal level and 1 is the maximal level for the scale ( Geras’kin & Chkhartishvili, 2017).
The required level of information security risk depends on the type of membership function. The trapezoidal and triangular functions meet the most stringent requirements. The confidentiality scale of information blocks,
Values for membership functions:
The integrity level of information blocks,
The value scale of information blocks,
The scale of external influence on information blocks,
The vulnerability assessment scale for the outer boundaries of the DLT register,
Research Questions
The efficiency of information protection is related to the level of probability of an information threat occurring, which depends on the potential of the source of the security threat for the related vulnerability.
Presented in the form of inference rules below are the data showing the relationship between the potential of the source of the security threat and the related vulnerability:
where
Rule (
Rule (
The logic of rule (
According to the calculated probability of the threat occurring, it is necessary to determine the degree of the negative impact for the protected information ( Geras’kin, 2018). The degree of impact is the result, in the form of loss value, of the threat to protected information occurring in relation to the associated vulnerability of the information system. Input data for impact analysis are the value of protected information and its criticality.
We define the criticality property as the degree of importance of information about the tools and methods for providing information security that protect the company’s principal (critical) business processes. If it occurs, a threat that exploits the vulnerability in question leads to the loss of confidentiality, availability, and integrity of protected information resources ( De Gusmão, Silva, Silva, Poleto, & Costa, 2016).
Loss caused by information security risks can be quantified, for example, by the amount of lost profits or the costs of restoring lost data. There is also an approach to qualitatively assessing loss based on the use of an impact scale. Let us look at the advantages and disadvantages of the approaches to assessing information impacts ( Groumpos, 2016). The uncertainty inherent in the approaches requires analyzing additional information. That information may include the frequency of and costs resulting from the vulnerability as well as weight factors. The cost of vulnerability and the frequency of its occurrence under the influence of a specific threat to protected information are determined for a specific period. Information security risks are assessable with a method consisting in the pairwise multiplying of probabilities of the threat to protected information occurring by the magnitude of the loss caused by the threat ( Galbusera & Giannopoulos, 2018). The products then need to be ranked. This technique is recommended in National Institute of Standards and Technology Special Publication 800-39 NIST SP 800-39 and British Standards Institute Code of Practice for Information Security Management BS 7799 (ISO 17799) (2019), the only difference being that the dimension of the matrix of probability and loss is 3×3 for NIST and 5×5 for BS 7799.
Product ranking involves the use of conventional risk values. The level of the related risk reflects the probability of the threat to protected information occurring under the influence of the corresponding vulnerability ( Alfonso, Roldán López de Hierro, & Roldán, 2017).
When using fuzzy-logic tools in the form of an inference mechanism, one can express the presented method for estimating information security risks as the following inference rules.
Input variables:
Output variable:
Logical-inference rules:
In the inference rules, one can supplement the output conditions or change the number of input variables. Once elaborated, the rules will significantly improve the accuracy of assessing information security risks and the applicability of this method in practice. The final stage of assessing information security risks is making the final report. The management needs that report to make efficient and timely decisions on strategic development, personnel policy, attracting investments, reengineering business processes, and optimizing all types of costs involved in managing corporate resources.
The report must contain accurate and easy-to-understand recommendations for reducing potential loss resulting from the occurrence of all possible information threats that exploit the related vulnerabilities. In essence, the fuzzy-inference mechanism consists in converting input variables to output ones, or a quantification of risk.
At the initial stage, it is necessary to determine input variables for the model. Data for the input variables were obtained with the Delphi method. This called for identifying relationships between the estimated parameters with the logical rule
Purpose of the Study
The principal step in using the premises and mathematical tools of fuzzy-set theory to describe and formulate a model for information security risks is to identify additional object sets – measuring scales and assessment functions. A set of objects that represent measuring scales can be fuzzy, discrete, or continuous. Existing functions for fuzzy assessment of information security risks can be used as a set of assessment functions.
Research Methods
We propose using a generalized formal fuzzy-estimation algorithm to solve the problem of mathematically modeling potential information security risks that come with blockchain technology. The proposed method is based on the mathematical tools of fuzzy-set theory. This made it possible to determine the form of presenting the model for the information security risks of blockchain and formulate an algorithm for assessing information security risks. In essence the method complies with the recommendations of the international standard NIST SP 800-39 for managing information security risks.
Findings
The use of the fuzzy-inference mechanism is based on the use or development of an input-data-processing algorithm. The resulting algorithm must correspond to the study area in that it reflects the relationship between input and output variables or in that it yields various representations for the input data. Given the nuances of providing information security to evaluate information security risks, the Mamdani and Sugeno algorithms can be used. The problem at hand consists in assessing information security risks with fuzzy-logic rules and five-level scales for input variables ( Korablev & Petrushova, 2019).
The surface view of the fuzzy inference in figure
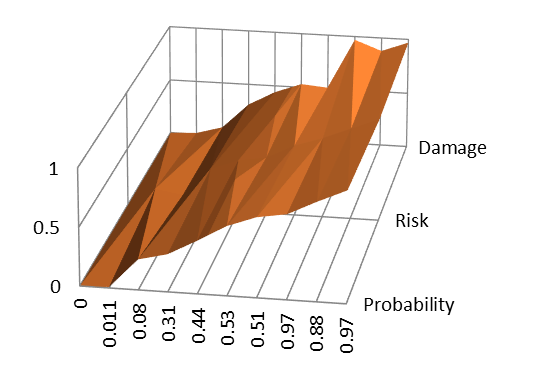
In the figure 01we can see a fairly smooth surface of the plot, which determines the correctness of the inference rules. Fuzzy-inference surfaces can be used to monitor the quality of the fuzzy-inference mechanism. A visual analysis of plots revealed a borderline value of the information risk indicator (0.48), which depends on the potential of the intruder with respect to certain threats.
Conclusion
The fuzzy-inference mechanism is a comprehensive approach to fuzzy modeling since it allows one to factor in the degree of the quality of assessing how effective the security of information resources is (using the associated fuzzy scale); the required level of protection; and the logical-inference rules that determine the variable of the information security risk. Practice shows that the use of toolkits for implementing the fuzzy-inference mechanism makes it possible to simplify information risk management through the use of graphic components. This makes it possible to involve ordinary employees in assessing risks.
References
- Alfonso, G., Roldán López de Hierro, A. F., & Roldán, C. (2017). A fuzzy regression model based on finite fuzzy numbers and its application to real-world financial data. Journal of Computational and Applied Mathematics, 318, 47-58. https://doi.org/10.1016/j.cam.2016.12.001
- British Standards Institute Code of Practice for Information Security Management (BS 7799/ISO 17799) (2019). Retrieved from: http://www.all.net/books/audit/bs7799.html Accessed: 10.07.2019.
- De Gusmão, A. P. H., Silva, L. C., Silva, M. M., Poleto, T., & Costa, A. P. C. S. (2016). Information security risk analysis model using fuzzy decision theory. International Journal of Information Management, 36(1), 25-34. https://doi.org/10.1016/j.ijinfomgt.2015.09.003
- Galbusera, L., & Giannopoulos, G. (2018). On input-output economic models in disaster impact assessment. International Journal of Disaster Risk Reduction, 30, 186-198. https://doi.org/10.1016/j.ijdrr.2018.04.030
- Geras’kin, M. (2018). Modeling reflexion in the non-linear model of the stakelberg three-agent oligopoly for the Russian telecommunication market. Automation and Remote Control, 79(5), 841-859. https://doi.org/10.1134/S0005117918050065 [in Rus.].
- Geras’kin, M., & Chkhartishvili, A. G. (2017). Structural modeling of oligopoly market under the nonlinear functions of demand and agents’ costs. Automation and Remote Control, 78(2), 332-348. https://doi.org/10.1134/S0005117917020114 [in Rus.].
- Groumpos, P. P. (2016). Modelling business and management systems using fuzzy cognitive maps: A critical overview. International Journal of Business and Technology, 4(2), 2. https://doi.org/10.33107/ijbte.2016.4.2.02
- Korablev, A. V., & Petrushova, M. V. (2019). A fuzzy mathematical model for managing the digital transformation of business processes based on cloud services, Espacios, 40(18), 16.
- Korablev, A. V. (2016). The use of cloud technologies in banking. Journal of Economy and Entrepreneurship, 8(73), 463-468. [in Rus.].
- Korablev, A. V., Petrushova, M. V., Pogorelova, E. V., & Abrosimov, A. G. (2019). Mathematical model of economical assessment of investments in information provision for the management system of a modern company. In V. Mantulenko (Ed.), Proceedings of the 17th International Scientific Conference “Problems of Enterprise Development: Theory and Practice” 2018. SHS Web of Conferences, 62 (11002). Les Ulis: EDP Science. https://doi.org//10.1051/shsconf/20196211002
- Luo, J. -L., & Hu, Z. -H. (2016). Risk paradigm and risk evaluation of farmers cooperatives' technology innovation. Economic Modelling, 44, 80-85. https://doi.org/10.1016/j.econmod.2014.10.024
- Masneva, M. F., & Petrushova, M. V. (2016). Internet portals of public services in electronic form. Journal of Economy and Entrepreneurship, 2-1(67), 130-133. [in Rus.].
- National Institute of Standards and Technology Special Publication 800-39 (NIST SP 800-39). Retrieved from: https://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication800-39.pdf Accessed: 13.07.2019.
Copyright information

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
About this article
Publication Date
09 March 2020
Article Doi
eBook ISBN
978-1-80296-078-5
Publisher
European Publisher
Volume
79
Print ISBN (optional)
-
Edition Number
1st Edition
Pages
1-1576
Subjects
Business, business ethics, social responsibility, innovation, ethical issues, scientific developments, technological developments
Cite this article as:
Korablev*, A. V., Petrushova, M. V., & Sakova, T. G. (2020). Mathematical Modeling Of Information Security Risks Inherent In Using Blockchain Technology. In S. I. Ashmarina, & V. V. Mantulenko (Eds.), Global Challenges and Prospects of the Modern Economic Development, vol 79. European Proceedings of Social and Behavioural Sciences (pp. 1163-1169). European Publisher. https://doi.org/10.15405/epsbs.2020.03.167