
Methods Of Artificial Intelligence In The Educational Process Of The University


Abstract
In present-day economic conditions, a new management paradigm has emerged. According to this paradigm the main source of the organization’s earned value is not material capital, but people who have knowledge and conditions for the implementation of the goals of the enterprise. Personnel audit in an organization is the most difficult element of personnel management. Essentially, audit is characterized by some activities, in terms of which assessments of the employees and the results of their activities are formed. When constructing such an assessment, it is necessary to identify to what extent the results of the contractor’s work correspond to the desired goals and regulatory requirements. When conducting an audit of human capital, highly trained specialists are needed in the field of economics, human resources and management. The auditor must identify the key skills needed by employees to achieve the organization’s core objectives and has an interest in identifying employees whose knowledge and skills are used not in full. To form objective assessments of personnel during an audit, it is offered to use machine learning methods, the results of which are a kind of assistants to auditors when deciding on the quality of work of a particular performer. The methods of classification in a situation where employees need to be divided into specific categories according to the degree of their labour efficiency are considered in this article.
Keywords: Artificial intelligence, machine learning, typical management tasks
Introduction
Artificial intelligence (AI) refers to information and communication technologies (ICT) that can sense, understand, act and learn. Such technologies allow computers to perceive the world (computer vision, sound and sensor processing), analyze and understand the information gathered (natural language processing), make informed decisions or recommend actions (inference mechanism or expert systems), and learn from experience (machine learning). Intelligent machines are computers and applications with built-in AI. Intelligent systems combine machines, processes and people (Kolbjørnsrud et al., 2016). According to various international reports, AI in education (Artificial Intelligence in Education - AIEd) is one of the developing trends in learning technologies. However, the pedagogical benefits of this trend on a larger scale are still unclear for teachers, as well as the impact it may have really on teaching and learning process in higher education (Zawacki-Richter et al., 2019).
It would be naive to think that AI has no impact on education - on the contrary, the possibilities here are enormous, but so far they too have been exaggerated. Every new technology goes through a period of intense growth in reputation and expectations, followed by a precipitous fall: a new phenomenon inevitably ceases to meet the expectations, after which growth will slow down as the technology is developed and integrated into our lives.
The application of AI in education has been the subject of research for about 30 years. In 1997 the International Society for the Use of AI in Education was founded, and the first issue of International Journal of AIEd was published. However, in a broader sense, educators have simply begun to explore the potential pedagogical opportunities that AI applications provide to support students throughout the student life cycle.
When researching the problem of introducing AI into education, two main questions appear (Holmes et al., 2019):
- what to teach students in the age of AI
- how do we teach
Answering the first question, it is necessary to justify need of focusing on broad, deep and diverse education being a barrier against uncertain future, which, in turn, means an increased focus on deeper learning goals of modern education.
Answering the second question, it is important to distinguish between educational technologies in general, and AI in education, in particular. The article suggests the authors' interpretation on the introduction of AI in the educational process of the university. At the same time, special attention is paid to the practical side of teaching students in modern conditions, i.e. the forming of skills and abilities to use AI methods in solving practical problems, which is the main goal of this article.
Problem Statement
In the context of higher education, the concept of the student life cycle can be used as a basis to describe various services using AI at a broader administrative level, as well as to support academic teaching and learning in a narrower sense. The research objective of this article is to find answers to questions related to the implementation of AI methods in the educational process of students throughout the entire life cycle.
Today, colleges and universities use a wide range of AIEd tools that can be viewed from three different angles (Baker & Smith, 2019):
- on the part of the side of the learner (student)
- on the part of the trainer
- from the side of the system
In the first case, such tools are learning-oriented: software used by students to receive and understand new information that responds to the individual student's need.
In the second option, teacher-centered systems are used to support the teacher and reduce their workload by automating tasks such as administration, assessment, feedback and plagiarism detection. The AIEd tools also provide insight into student performance so that the teacher can offer support and guidance as needed.
The third category represents the least common type of AIEd with the fewest existing instruments. Often such tools provide information for administrators and managers at the institutional level, for example, for tracking dropout patterns across university departments. System tools are used for a wider range of tasks than tools of the first two categories, in particular for scheduling and for forecasting of inspections.
Teaching students in AI methods implies the ability of students to apply the knowledge gained in practice, to use the necessary software tools, form conclusions based on the results obtained, and to plan the further course of research. As you know, an important part of AI is machine learning (ML) (Russell & Norvig, 2010). The methods that are used in AI to work with data are part of the ML. The term "machine learning" refers to a technology that is defined in (Alpaydin, 2010) as follows: "Optimization of model performance criterion using data and past experience." In ML, data plays an important role, and a learning algorithm is used to discover and learn knowledge or properties from data. The quality or quantity of a dataset has an impact on the efficiency of learning and forecasting. The purpose of ML is to offer methods that allow to learn from data and make predictions. The power of ML lies in its ability to overcome programming instructions by simulating inputs and forming predictions or decisions. Given the importance of ML, the primary objective when introducing AI methods into the educational process is to teach students the methods and techniques of ML. It is necessary to emphasize the purposeful nature of the study of ML methods to such a level that students can solve real practical problems using the appropriate software. This is the problem posed in this article.
Research Questions
The list of questions to be investigated in this work consists of the following set:
- What are the most important machine learning techniques for students to learn?
- How to create a database on the basis of which a model of ML is selected?
- How to choose the best model?
- How to evaluate the obtained result in terms of its suitability for the task at hand?
- How to use the fitted model to solve the problem?
- How to assess the knowledge and skills of students when teaching them ML methods?
The answers to the questions posed constitute the content of this article.
Purpose of the Study
The aim of the research is to consider the methods of AI and ML from the point of view of their inclusion in the learning process of university students. Such an analysis involves the selection of typical tasks; analysis of the methods most suitable for their solution; evaluation and comparison of the selected methods according to the achieved accuracy; formation of practical tasks for students on the basis of selected tasks and their solutions.
Research Methods
ML is programming computers using data or past experience. We have a model defined to within some parameters, and training is the execution of a computer program to optimize the parameters of the model using training examples or past experience. The model can be predictive for making predictions for future time intervals, or descriptive for gaining knowledge from the data. But machine learning isn't just a database problem; machine learning is part of AI. In order to be intelligent, a system that changes under the influence of the environment must be able to learn. If the system can learn and adapt to such changes, the system designer does not have to anticipate and provide solutions for all possible situations. Machine learning algorithms use computational techniques to "learn" information directly from data, without relying on a predefined equation as a model. Algorithms adaptively improve their performance as the number of samples available for training increases (Lee & Shin, 2020). The name ML implies that the described method analyzes the data and finds the model on its own, and not with the help of a person.
In the following, we will consider the tasks that are encountered when teaching students in the direction of the Master's degree program "Management". The choice of disciplines from this area is due to the importance of the management problem, which occurs in almost all areas of the economy.
Database creation
Two approaches can be taken to create a database of examples used in ML to build a model:
- collect real data.
- form a toy dataset.
In various tasks, both methods of data generation will be applied, but the second approach is preferred. In ML, it is important to learn how to use such sets correctly, since learning algorithms based on real data is difficult and may fail (Ramsundar & Zadeh, 2018). Toy datasets play a critical role in understanding how an algorithm works. Simple synthetic data sampling simplifies the situation and allows you to assess whether the algorithm has learned the required rule or not.
Machine learning in management
There are a wide variety of ML methods suitable for solving problems from various fields. The authors, taking into account their extensive experience in teaching disciplines in the field of management, propose a scheme of ML methods shown in Figure 1. The diagram shows, in general, known techniques and methods, but their set, according to the authors, is quite sufficient for solving most problems in the field of management.
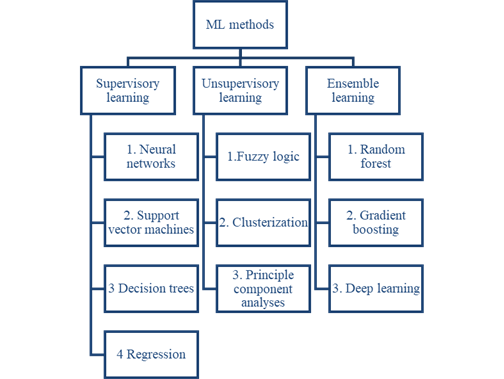
As can be seen from Figure 1, all methods are grouped into three clusters. If the first two do not raise any questions, then the third group requires some explanation. The idea of ensemble learning is to build a predictive model that combines the results of simpler basic models (Hastie et al., 2009). Ensemble learning uses multiple learning algorithms at the same time in order to obtain more accurate predictions than individual models. Ensemble methods are essentially an ML paradigm where multiple models (often called "weak learners") are trained to solve the same problem and combine to produce better results. The main hypothesis is that with the right combination of weak models, more accurate and / or reliable models can be obtained (Kuncheva, 2004).
Next, we indicate the typical tasks encountered in management and briefly demonstrate their solutions using the methods indicated in the diagram in Figure 1. Quite often, managers need to solve the following tasks:
- determine the credit rating of the borrower;
- describe the degree of staff motivation;
- predict the time series of the development of the situation.
Naturally, other tasks are encountered in the practice of management. Each managerial specialist will name other problems that, in his opinion, are encountered most often in his practice. However, the principle of demonstrating the solution of such problems and their introduction into the practice of teaching students by creating laboratory works, practical tasks and other educational activities is important for us.
Methods of solution
When solving the above problems, we will apply the following methods from the diagram in Figure 1:
- for credit rating - support vector machine;
- to motivate personnel - fuzzy logic;
- for forecasting a series - a recurrent neural network.
Let us briefly describe each of the methods.
The Support vector machines (SVM) is a method for the classification of both linear and non-linear data. The SVM uses a nonlinear mapping to renovate the unique training data into a higher dimension. Surrounded by this new dimension, it examines the linear optimal separating hyper plane sorting out the tuples of one class from another. This method in the late 70s. the last century was developed by Russian scientists Vapnik and Chervonenkis. (as cited in Vapnik, 1998). With a suitable nonlinear mapping to a necessarily high dimension, data from two classes can always be separated by a hyperplane. The SVM finds the hyperplane using support vectors and margins. Although the training time of even the fastest SVMs can be exceedingly slow, they are accurate, and exemplary in their ability to model complex nonlinear decision boundaries. They are much less prone to over fitting as compared with other methods. SVM initiates also provide a compact description of the learned model. SVMs can be used for prediction, along with classification. They have been applied to several areas, including handwritten digit recognition, object recognition, and speaker identification, as well as benchmark time-series prediction tests.
Fuzzy logic (FL) uses fuzzy set theory as its main tool. The founder of IP is Lotfi Zadeh, who created IP as a scientific discipline. Our understanding of most physical processes is largely based on imprecise human reasoning. This inaccuracy compared to the exact values required by computers, however, is still a form of information that can be quite useful to humans. The ability to implement such reasoning into still unsolvable complex problems is, in essence, a criterion for assessing the effectiveness of IP (Ross, 2010).
Undoubtedly, this ability cannot solve problems requiring precision, such as the manufacture of precision parts. The requirement for precision on a number of products leads to high demands on cost and production and development time. For all but the simplest systems, costs are proportional to accuracy: the greater the accuracy, the higher the cost. When evaluating the use of an IL for a given problem, the engineer should consider the need for it.
Making decisions about processes that contain non-random uncertainty, such as uncertainty in natural language, is not infallible. The idea, proposed by L. Zadeh, is that belonging to a plurality is the key to making decisions in conditions of uncertainty. IP focuses on linguistic variables in natural language and seeks to provide a framework for approximate reasoning with imprecise sentences. Linguistic variables in this theory are those variables whose values are represented by natural or artificial words or sentences. IP reflects both the correctness and the vagueness of natural language in common sense reasoning. L. Zade expanded the concept of a binary degree of membership from a real continuous interval [0, 1], characteristic of clear logic, to an infinite number of values between the end points of the interval [0, 1]. In CL, such values represent different degrees of membership of an element x to a certain set X. Such sets were called fuzzy by L. Zade.
Recurrent neural network (RNN) is a type of neural network where connections between elements form a directed sequence. This makes it possible to process a series of events in time or sequential spatial chains. Recurrent networks can use their internal memory to process sequences of arbitrary length. Long short-term memory (LSTM) is a special kind of recurrent neural network architecture capable of learning long-term dependencies, proposed in 1997 by Hochreiter and Schmidhuber (1997). Long Short-Term Memory Network is the most popular RNN architecture at the moment, which can study long-term relationships between time steps of a sequence.
The main components of an LSTM network are the sequence input layer and the LSTM layer. The first layer injects time series data into the network. The LSTM layer examines the long-term relationships between the time steps of a series. The LSTM network architecture is shown in Figure 2.
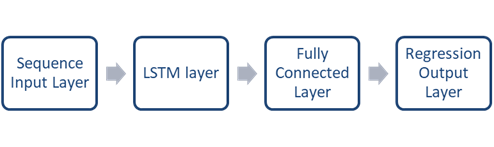
The first layer of the network is the serial input layer, followed by the LSTM layer. The network ends with a fully connected layer and a regression output layer.
Findings
Here are the brief results of solving these problems. For the credit rating problem, six variables characterize the following attributes of clients: X1 - loan term (months); X2 - loan amount (USD); X3 - work for the employer (years); X4 - gender of the client (1 - man; 2 - woman); X5 - age (year); X6 is the number of previous loans in this bank. The output is a categorical variable consisting of two values: good, bad. As a problem solver, we will choose a classifier in the form of an SVM with a different type of kernel: Gaussian, linear, and quadratic.
The best accuracy is demonstrated by the SVM with a square root. Figure 3 shows a receiver operating characteristic (ROC) curve that shows the proportion of true positive rates (TPR) as a function of the proportion of false positive rates (FPR) for the selected classifier.
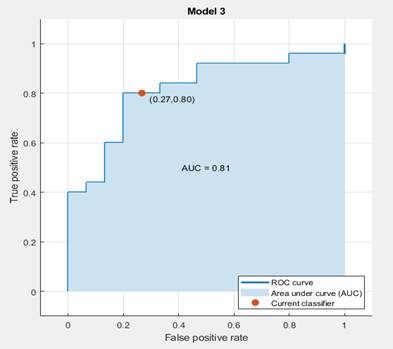
In the graph below, the ideal error-free classification result is a line forming a right angle in the upper left corner of the graph. A bad result, which is no better than a random one, is shown by a line running at an angle of 45 degrees from the lower left corner of the graph to the upper right corner. The Area Under Curve (AUC) number is an indicator of the overall quality of the classifier. The higher the AUC value, the better the quality of the classifier. The marker shows the values of the FPR and TPR indicators for the selected classifier. For example, the proportion of false positive classifications, FPR = 0.27, indicates that the classifier incorrectly assigns 27% of observations to a positive class (good). TPR = 0.8 indicates that the current classifier correctly assigns 80% of observations to a positive grade.
To predict the class of a new observation, after creating the model, export it to the workspace. As a result, the trainModel structure is formed, which is used for forecasting using new data. As an example, below is the result of classifying the new vector km_6 = [36; 15000; 0; 2; 24; 3]:
>> yfit = trainedModel.predictFcn(km_6)
yfit =
categorical
bad.
Thus, the classifier classified this observation as bad.
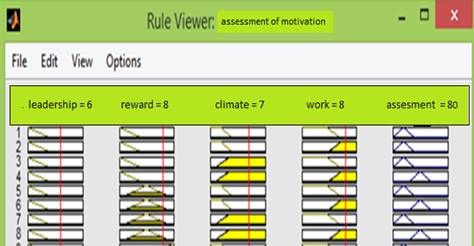
In the second task of assessing the motivation of personnel, we use the technique proposed by B. Tracy (Tracy, 2013), which identified four factors operating in each firm and influencing the motivation of personnel. These four factors are: leadership style; reward system; organizational climate; the nature of the work. The quantitative result of the decision (the result of motivation) with the point values of the input variables: 6; eight; 7; 8 is 80 points on a 100-point scale. Figure 4 shows the results of calculations using fuzzy logic.
Finally, in the third task, a forecast of a time series was constructed, played out according to the following formula:
yt = 0.2t + 0.2t * sin (t) + N (0.0.5),
where N (0.0.5) is a normally distributed random variable with zero mean and standard deviation equal to 0.5.
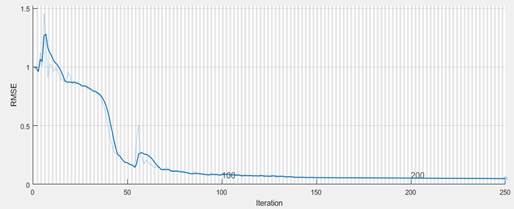
The prediction was carried out using the long short-term memory network LSTM in the MatLab package. Figure 5 shows a graph of the learning process for such a network.
The predicted values of the time series are shown in Figure 6 (together with the original series).
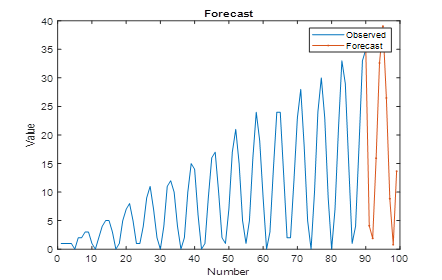
The original 100-point series was divided into two parts: 91 points were selected for training, 9 points for testing. The forecast is shown on the test sample, from which it can be seen that the nature of the predicted series is preserved.
Conclusion
The introduction of AI methods into training programs corresponds to the priority project of Russia "Modern digital educational environment in the Russian Federation". The digital economy requires competent personnel, and for their training it is necessary to properly modernize the education and vocational training system, to bring educational programs in line with the needs of the digital economy, which is based on artificial intelligence. At the State University of Aerospace Instrumentation (SUAI), where the authors work, work programs have been created in a number of disciplines with the introduction of elements of artificial intelligence and machine learning, methodological instructions have been developed for the implementation of coursework by discipline, teaching aids. In addition, software systems for laboratory work and practical tasks in various disciplines, developed using MatLab, Statistica, have been introduced. Computer labs are equipped with licensed versions of these software products, and students perform calculations using machine learning technologies.
References
Alpaydin, E. (2010). Introduction to machine learning, 2. Adaptive Computation and Machine Learning. Massachusetts Institute of Technology.
Baker, T., & Smith, L. (2019). Educ-AI-tion rebooted? Exploring the future of artificial intelligence in schools and colleges. https://media.nesta.org.uk/documents/Future_of_AI_and_education_v5_WEB.pdf
Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer.
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735-1780.
Holmes, W., Bialik, M., & Fadel, C. (2019). Artificial Intelligence in Education. Promises and Implications for Teaching and Learning. The Center for Curriculum Redesign, Boston, MA. https://curriculumredesign.org/wp-content/uploads/AIED-Book-Excerpt-CCR.pdf
Kolbjørnsrud, V., Amico, R., & Thomas, R. J. (2016). The promise of artificial intelligence: Redefining management in the workforce of the future. https://www.researchgate.net/publication/306039533_The_promise_of_artificial_intelligence_Redefining_management_in_the_workforce_of_the_future
Kuncheva, L. (2004). Combining pattern classifiers: methods and algorithms. John Wiley & Sons.
Lee, I., & Shin, Y. (2020). Machine learning for enterprises: applications, algorithm selection, and challenges. Bus Horiz, 63(2), 157-170. DOI:
Ramsundar, B., & Zadeh, R. (2018). TensorFlow for Deep Learning. O'Reilly, Beijing-Boston.
Ross, T. J. (2010). Fuzzy Logic with Engineering Applications. John Wiley & Sons.
Russell, S. J., & Norvig, P. (2010). Artificial Intelligence A Modern Approach. Pearson Education.
Tracy, B. (2013). Motivation. AMA.
Vapnik, V. (1998). Statistical Learning Theory. J. Wiley.
Zawacki-Richter, O., Marín, V. I., Bond, M., & Gouverneur, F. (2019). Systematic review of research on artificial intelligence applications in higher education–where are the educators?. International Journal of Educational Technology in Higher Education, 16(1), 1-27.
Copyright information

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
About this article
Publication Date
25 September 2021
Article Doi
eBook ISBN
978-1-80296-115-7
Publisher
European Publisher
Volume
116
Print ISBN (optional)
-
Edition Number
1st Edition
Pages
1-2895
Subjects
Economics, social trends, sustainability, modern society, behavioural sciences, education
Cite this article as:
Antokhina, J. A., Krichevsky, M. L., & Martynova, J. A. (2021). Methods Of Artificial Intelligence In The Educational Process Of The University. In I. V. Kovalev, A. A. Voroshilova, & A. S. Budagov (Eds.), Economic and Social Trends for Sustainability of Modern Society (ICEST-II 2021), vol 116. European Proceedings of Social and Behavioural Sciences (pp. 1634-1644). European Publisher. https://doi.org/10.15405/epsbs.2021.09.02.182