
Development Of Methodological Recommendations For Computer Presentation Of Unique Technological Competences (Utc)


Abstract
The main goal of corporate knowledge bases (CKB) is to transform the knowledge and experience of employees into the intellectual capital of the enterprise. The Knowledge Base is an effectively managed centralized electronic archive of documents, reference books, classifiers and other formalized information materials of the company. An important part of the work on building a CKB is the identification, verbalization and machine representation of unformalized knowledge of employees, the central place among which is occupied by unique technological competences. In the paper it is developed a mathematical apparatus for representation of knowledge about UTC in information systems of decision-making, and the problem of its computer representation. The method of representation of knowledge about the unique technological competence on the basis of a network of finite automata is offered. The UTC representation given in the formats is designed, first of all, for the search for new directions of their use. Another use of the description of the UTC may require the addition of a knowledge representation with the necessary attributes. This approach makes it possible to effectively use knowledge about UTC in building information systems.
Keywords: Competitivenesskey competencesrepresentationfinite automata
Introduction
Solving the problem of commercialization of unique technological competences (UTC) of high-tech enterprises with the purpose of diversifying their activities requires the implementation of preliminary stages of work - identifying and describing UTC. The importance of the task was outlined in (Chursin, Shamin & Fedorova, 2017) and (Chemezov & Volobuev et al., 2017).
At the same time, the requirements for accuracy, completeness, adequacy and relevance to possible search queries of potential customers are imposed on the quality of the description of the UTC. It is necessary to ensure the simplicity of the perception of information and advertising language in the context of the interests of the customer and a clear identification of the distinctive characteristics of UTC. To this end, a description format has been proposed that includes attributes (predicate, object and quantitative characteristic, proving the distinctive characteristics of the UTC) and similarly described UTK lower levels, explaining why these unsurpassed UTC top-level characteristics are achieved. Together, UTCs of various levels with links represent a tree-like information structure (Kashirin, Strenalyuk & Chursin, 2018).
Problem Statement
As already noted, the solution of the problem of commercialization of unique technological competences is closely connected with the efficiency of computer representation of information about them. If there is a modern and effective computer representation of knowledge about the company's UTC, it becomes possible to use them in information systems and automated systems of logical inference and decision-making.
When creating information systems, it is necessary to use modern mathematical methods, which must be based on methods of discrete mathematics.
In this paper, we propose using finite machine approaches to represent knowledge of unique technological competencies. This approach, in particular, is very effective in constructing automated systems of logical inference (expert systems). The use of models based on finite state machines allows us to obtain a formal description of the processes of processing data on UTC, which will take into account various aspects of the knowledge model. Since finite-automaton models can describe complex data processing, the use of finite state machines makes it possible to efficiently process the knowledge base.
In the process of functioning of the automated system of logical inference it is assumed that the representation of knowledge in the form of a network of finite state machines can change with time depending on the replenishment and / or actualization of knowledge.
Research Questions
The search of a language, models, and tools to represent unique technology competences for programming and database needs.
Purpose of the Study
Development of the methodology for represent unique technology competences as a set of data to be used in IT solutions.
Research Methods
Computer science methods, theory of databases
Findings
The application of this description to search for commercialization options in a digital economy requires the use of adequate computerized information about UTC for further inclusion in Internet technology transfer resources, portals of publication of "calls" for "solvers" such as www.innocentive.com or www.yet2.com , Internet catalogs of objects of scientific and technological potential, communication platforms of open innovations, crowdsourcing platforms and technology brokerage sites and other information resources. As a rule, all these Internet sites use a simple format of commercial offers and information about the UTC for a potential customer should be presented in this form, taking into account the terminology and expectations of the target market. However, in order to expand the potential for diversification, to gain opportunities to offer the various markets the competence of the advanced teams of the organization to develop a certain type of products or solve the scientific and technical problem of a particular class, it is useful within the organization to have a complete description of all the UCS conditioning each other in an adequate hierarchical tree view, can be used to promote specific UTCs as needed. Such a description can be stored and updated in the corporate knowledge base and published in Internet resources through a specific interface on behalf of the organization itself, the technology broker, the supporting university, etc.
In modern literature, the knowledge base (in the broad sense) is called an effectively managed centralized electronic archive of documents, directories, classifiers and other formalized information materials of the company. The main goal of corporate knowledge bases (KBZ) is to transform the knowledge and experience of employees into the intellectual capital of the enterprise. In the narrow sense, the knowledge base is a semantic model that describes the subject area and allows one to answer such questions from this subject area, the answers to which are not explicitly present in the database. In this sense, the knowledge base is the main component of intellectual and expert systems. An important part of the work on building a CKB is the identification, verbalization and machine representation of unformalized knowledge of employees. In both cases, CKB is a battery of experience and capabilities of the enterprise, the central place among which is occupied by UTC.
The use of computer information systems ensures rigor, completeness, coherence, integrity and consistency of information, the ability to avoid multiple repetitions when entering and processing it. However, for this an adequate model and data structure must be implemented, appropriate templates for input and processing of information are developed. To select the data model and the type of information presentation, the natural structure of the processed information is analyzed, its formalization and further choice of tools for building the information system (IS). Information in modern IP is divided into data and knowledge. Consider the differences.
Data are usually referred to as information obtained as a result of an experimental study of objects, processes, and phenomena of the subject (problem) area under investigation. A numerical data type is often used for subsequent mathematical processing.
The database is a computer data store containing numeric and symbolic arrays, tables, graphs, graphs and other information about the software. The database is characterized by a large volume and relatively low cost of information.
Knowledge reflects the properties and patterns (laws, principles, relationships, rules, signs, etc.) of the researched PPO, obtained by using the professional experience of specialists in this PPO, as well as from publications, documents and other sources of information. Knowledge differs from data by the greater complexity, abstractness, completeness and versatility of the description of PPO. The text type of the view is often used. These differences of knowledge from data approach the human concept, perception and handling of information.
The knowledge base is a repository of knowledge about the properties and laws of the subject domain studied, obtained from experienced specialists, from publications, documents and other sources of information. The knowledge base is characterized by a relatively small volume and a high unit cost of information.
At the heart of modern BZ is the use of so-called semantic technologies, the automated processing of conceptualized knowledge. To date, all the necessary components of the methodology and technologies necessary for working with ontological models have been created, which are subject to processing with the help of semantic technologies. The word "ontology" means the totality of knowledge; the term "semantic technologies" emphasizes the fact that they provide work with the meaning of information. Thus, the transition from traditional IT to semantic technology is the transition from working with data to working with knowledge. The difference between these two terms, which we use here solely as applied to the content of information systems, emphasizes the difference in the way information is used: for the perception and use of data, it is necessary for a person to perform an interpretation, to identify their meaning and transfer it to an interesting part of reality (in those cases, when the program algorithm does this - the situation does not change fundamentally, since the way of interpreting the data is still given by the person). The knowledge presented in electronic form can be perceived directly, since they are already expressed with the help of the conceptual apparatus used by man. In addition, with this knowledge (ontologies), fully automatic operations can be performed - obtaining logical inferences. The result of this process will be new knowledge.
Consideration of the natural information structure of the description of UTC (Kashirin, Strenalyuk & Chursin, 2018), indicates the appropriateness of using forms of information representation, characteristic for the representation of knowledge.
In modern knowledge bases use the following forms of knowledge representation:
products,
frames,
semantic networks.
Semantic network - a structure for representing knowledge in the form of nodes connected by arcs. The very first semantic networks were developed as a proxy for machine translation systems, and many modern versions are still similar in their characteristics to the natural language. However, the latest versions of semantic networks have become more powerful and flexible and constitute a competition to frame systems, logical programming and other presentation languages.
The most suitable form of knowledge representation for the description of the UTC are semantic networks.
Since the late 50s of the last century dozens of variants of semantic networks have been created and put into practice (Bessmertnyy, 2010). Despite the fact that terminology and their structure are different, there are similarities inherent in almost all semantic networks:
Nodes of semantic networks are concepts of objects, events, states;
Different nodes of the same concept refer to different values, if they are not labeled, that they belong to the same concept;
Arcs of semantic networks create relations between nodes-concepts (marks over arcs indicate the type of relationship);
Some relations between concepts are linguistic cases, such as an agent, object, recipient and instrument (others mean temporal, spatial, logical relations and relations between individual sentences;
Concepts are organized according to levels in accordance with the degree of generalization, as, for example, the essence, living being, animal, carnivore.
However, there are also differences: the concept of meaning in terms of philosophy; methods for representing quantifiers of generality and existence and logical operators; ways of manipulating networks and rules of inference, terminology. All this varies from author to author. Despite some differences, the networks are convenient for reading and processing by a computer, and also powerful enough to represent the semantics of a natural language.
One of the types of semantic networks that reflect the relationship of "action" are "graphs with a center in the verb" or "graphs of Rastie."
At the heart of this model is not a concept, but an action or event. The subject or agent of the action and its object are introduced. A graph with a center in a verb allows you to dispense with nested graphs.
Graphs with a center in a verb are relational graphs, where the verb is considered the central link of any sentence. Markers of time and relationships are written right next to the concepts that represent the verbs. The graphs of Roger Schenk's conceptual dependencies also use this approach.
Despite the fact that graphs with a center in the verb are quite flexible in their structure, they have a number of limitations. One of them is that they do not draw a distinction between the determinants that apply only to the verb, and the determinants relating to the whole sentence.
Networks with the verb in the center (the Rastie network) operate with the following types of links given in Table
A concrete implementation of the representation of the description of the UTC using this approach can be performed on the instrumental tool (knowledge representation language) that will be chosen for constructing the CKB. Demonstration and conceptual debugging of the possibility of this presentation can be carried out on more simple software tools.
It should be noted that the presentation of knowledge is a very complex and creative process. The main problem here is that the creation of a knowledge base almost always begins "from scratch"; thus there are no so called. knowledge of the elementary level, which a person acquires, from early childhood. Creation of such databases of domestic knowledge has been conducted for more than 25 years by Cycorp. (www.cyc.com), however, according to the recognition of its founder Douglas Lenat, the car still needs to be explicitly informed that parents are older than their children and that people stop writing newspapers when they die . Knowledge of a particular subject area can be divided into common for all specimens and individual for each. Obviously, if formalization of knowledge for a class of objects is performed once, then it can be used by other authors when describing individual instances.
Thus, the formalization of knowledge of any domain should be based on knowledge of a more general level, describing the basic relationships between objects and the general properties of objects. Such knowledge is called ontology. For example, the ontology for describing the class "person" may contain the "has part" relationship with the objects "hand", "head" and the property "has a name", "has a date of birth", etc.
The application of such knowledge to lower-level objects is carried out using the rules of inheritance:
If X AKO Y and Y AKO Z then X AKO Z – if X is a subset of Y, and that, in turn, is part of an even larger set Z, then the class X is a subset of Z.
If X ISA Y and Y AKO Z then X ISA Z – if X is an instance of class Y, and that, in turn, is part of the set Z, then X is an instance of class Z.
If X has_part Y and Y has_part Z then X has_part Z – if X has in its composition Y, and that, in turn, has an integral part of Z, then X has in its composition Z.
If X ISA Y and Y has_part Z then X has_part Z – if X is an instance of class Y, and that, in turn, has a component part of Z, then instance X has Z in its composition.
If X AKO Y and Y has_part Z then X has_part Z – if X is a subset of Y, and that, in turn, has a component part of Z, then class X has Z in its composition.
If X ISA Y and Y has_a Z then X has_a Z – if X is an instance of class Y, and that, in turn, has property Z, then instance X has the property Z.
If X AKO Y and Y has_a Z then X has_a Z – if X is a subset of Y, and that, in turn, has the property Z, then the class X has the property Z.
Using inheritance rules allows the descriptions of all the properties of each instance to indicate only belonging to a class for which all the necessary properties have already been described. This approach is implemented in object–oriented programming systems.
Let us consider the application of the finite automaton model for the representation of knowledge about UTK. A finite state machine is a mathematical abstraction for the transformation of information. From a formal point of view, the finite automaton is the next five of ordered finite sets:
Here the following notation:
The operation of the finite state machine is defined as follows. The finite state machine operates at discrete instants of time
The idea of using finite state machines in the representation of knowledge is to describe not only the reflection on the input information, but also the mechanisms for assimilating the previously obtained information. In an effectively functioning expert system, as a knowledge base, not only the rules of logical inference, but also networks of finite automata, are used that allow to reflect rather complex logical connections. In a sense, using a network of finite state machines is analogous to artificial neural networks. At the same time, finite state machines have a number of advantages in engineering knowledge.
Under the finite state machine network, we will assume a set of finite automata that are linked together by means of oriented graphs in such a way that the output signals of some finite automata are input signals for other finite automata.
To demonstrate the possibility of computer representation of the description of the UTC and the development of the structure of knowledge, it is not necessary to use "heavy" and expensive intelligent software systems. In order to test the concept in advance, a software tool can be chosen that supports a graphic illustration of relationships and dependencies, for example, a simple non-relational database (NoSQL), which makes it possible to visually display the graph view.
Graph data bases can be used for this purpose. The graph model of the database is a generalization of the network data model and is distinguished by strong connections between nodes. Graphing databases are best suited for implementing projects that involve a natural graph structure of data - primarily social networks, as well as for creating semantic webs. In similar tasks, they are much faster than relational databases for performance, simplicity of making changes and visibility of information presentation.
The most well-known graphical DBMSs are ArangoDB, FlockDB, Giraph, HyperGraphDB, Neo4j, OrientDB.
For the analytical work with large volumes of data in the global graphs, specialized graph compute engines are used.
To illustrate the proposed approach of representing a description of a UTC in the form of the Rastie graph, an even simpler software tool can be used that has a description language, allows data input to a computer and a graphical output of the result.
Graphviz (http://www.graphviz.org/) is a package of utilities designed by AT & T specialists for automatic visualization of graphs given in the form of a text description. The package is distributed with open source files and runs on all operating systems, including Windows, Linux / Unix, and Mac OS. The most interesting program of the package is dot, an automatic visualizer of directed graphs that accepts a text file with a graph structure, and outputs a graph in the form of a graphic, vector or text file.
An example of a description of a fragment of the UTC structure in the form of a semantic network (the Rastie graph with the verb in the center) in the language of the description of DOT graphs is presented below. A fragment of the description of the UTC of Tesla Motors, discussed in more detail in (Kashirin, Strenalyuk & Chursin, 2018), is used:
The DOT program:
digraph g {
"providing mileage without recharging" -> "350 km instead of 150 km from competitors" [label = parameter]
"providing mileage without recharging" -> "development" [label = as]
"providing mileage without recharging" -> "electric vehicle" [label = object]
"development" -> "75kW * h instead of 18.7kW * h from the competitor" [label = parameter]
"development" -> "provision of electrical, explosion and fire safety" [label = as]
"development" -> "block AB" [label = object]
"development" -> "providing mileage without recharging" [label = goal]
"providing electrical, explosion, fire safety" -> "no precedents" [label = parameter]
"provision of electrical, explosion, fire safety" -> "batteries" [label = object]
"providing electrical, explosion, fire safety" -> "development" [label = goal]
}
Similarly, a large developed graph can be constructed that reflects the necessary number of nodes and connections between them for the semantic representation of the UTC of all levels, and the structure of the description of each level representing a separate competence is given by the same set of attributes (predicate, object, distinctive characteristic, "how "- go to the lower level).
Further, in order to search for commercialization options, the generalization procedure (induction) and the subsequent search for possible applications of UTC (deduction) should be applied to the "object" attribute.
Induction (Latin inductio - guidance, from Latin inducere - to entail, to establish) is a process of logical inference based on the transition from a particular position to a common one. Inductive reasoning connects private prerequisites with imprisonment not strictly through the laws of logic, but rather through some factual, psychological or mathematical notions.
Deduction (Latin deductio - reduction, reduction) is a method of thinking, the consequence of which is a logical conclusion, in which a private conclusion is derived from the general. The chain of reasoning (reasoning), where the links (statements) are linked together by logical inferences.
For example, in the example of Tesla Motors (fig. 1), the competence to provide high-capacity electric power, originally designed for on-board electric vehicle equipment, is applicable to electricity consumers in general (induction), including for households (deduction). Another example is given in (Chursin & Kashirin et al., 2018)
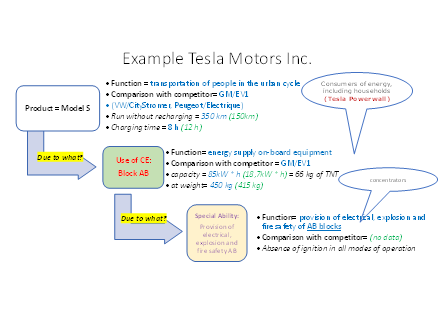

It is clear that the basis for this pair of procedures should be an adequate classification (taxonomy) that supports the necessary context. The choice of classifiers is a separate task of building an intelligent system. This can be a dynamic task of the knowledge base, and it can not be solved without using the proposed semantic approach.
Further, it is necessary to check the technological feasibility and economic feasibility of the possible commercialization option. First, a pool of preliminary directions can be generated, and then the necessary screenings are carried out, as a result, an array of proposals for the commercialization of each UTC from the description will be obtained. Interestingly, with the use of semantic modeling, the stage of "generating ideas" can be automated.
Conclusion
-
Submission of information on the UTC taking into account the levels, nesting and conditionality, combining the competencies of the lower levels to form the competencies of the upper levels is possible and realizable with the help of modern software tools. The choice of specific software for these purposes will be made taking into account the requirements of the developed KBZ, which can be used as a storage device for the subsequent interface with Internet resources of commercial promotion of UTK.
-
The information on UTC, presented in the form of developed formats, can be transformed for use in CKB in the language of knowledge representation chosen for it. In principle, the semantic processing of information about UTC can be automated.
-
The UTC representation given in the formats is designed, first of all, for the search for new directions of their use. Another use of the description of the UTC may require the addition of a knowledge representation with the necessary attributes.
-
The method of representation of knowledge about the unique technological competence on the basis of a network of finite automata is offered. This approach makes it possible to effectively use knowledge about UTC in building information systems.
Acknowledgments
This paper was financially supported by the Ministry of Education and Science of the Russian Federation on the project No.26.1146.2017/4.6 «Development of mathematical methods to forecast efficiency of using space services in the national economy»
References
- Bessmertnyy, I.A. (2010). Artificial Intelligence. Tutorial. SPb: SPbSU ITMO.
- Chemezov, S.V., Volobuev, N.A., Koptev, Yu.N. & Kashirin A.I. (2017). Diversification, competencies, problems and tasks. New opportunities. Innovations, 4(222), 3-27.
- Chursin, A.A., Kashirin, A.I., Strenalyuk, V.V. et al. (2018). The approach to detection and application of the company's technological competences to form a business-model. IOP Conference Series Materials Science and Engineering, 313, 012003. doi:10.1088/1757-899X/312/1/012003
- Chursin, A.A., Shamin, R.V. & Fedorova, L.A. (2017). The Mathematical Model of the Law on the Correlation of Unique Competencies with the Emergence of New Consumer Markets, European Research Studies Journal, 0(3A), 39-56. https://ideas.repec.org/a/ers/journl/vxxy2017i3ap39-56.html
- Kashirin, A.I., Strenalyuk, V.V. & Chursin, A.A. (2018). Development of a methodology for identifying, describing and searching for options for the commercialization of unique technological competencies at high-tech enterprises (in press)
Copyright information

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
About this article
Publication Date
23 November 2018
Article Doi
eBook ISBN
978-1-80296-048-8
Publisher
Future Academy
Volume
49
Print ISBN (optional)
-
Edition Number
1st Edition
Pages
1-840
Subjects
Educational psychology, child psychology, developmental psychology, cognitive psychology
Cite this article as:
Kashirin, A. I., Strenalyuk, V. V., & Artyakov, V. (2018). Development Of Methodological Recommendations For Computer Presentation Of Unique Technological Competences (Utc). In S. Malykh, & E. Nikulchev (Eds.), Psychology and Education - ICPE 2018, vol 49. European Proceedings of Social and Behavioural Sciences (pp. 246-255). Future Academy. https://doi.org/10.15405/epsbs.2018.11.02.27